
Analogies matter. They allow us to make sense of complex ideas. They also influence our thinking in ways that we don’t fully understand and might not be conscious of. But how often do we examine the analogies that we are using, to really explore the ideas we are conveying?
We’ve all heard that data is the new oil. It’s an easy comparison to make and on a superficial level, it makes sense. The phrase has become widely accepted since it was coined, seemingly by the architect of Tesco’s Clubcard, and then popularised by the Economist. Two years ago they published an article entitled, ‘The world’s most valuable resource is no longer oil, but data’.
There has been pushback since, with Antonio García Martínez writing in Wired that it is ‘supremely unhelpful to perpetuate the analogy’. I myself had previously written about data being the oil of the digital age, but without being able to really unpick what this means – what's helpful, what's not, what assumptions underlie this analogy and what impact does it have on our thinking more generally?
At the Health Foundation, we've been using data for some time to tackle problems in health care. We are now also exploring what more we can do to ensure that data and technology have a positive impact on our health. To help us develop our thinking, we held a roundtable on this oil analogy, inviting data leaders from UK health care as well as other sectors. Energy markets expert Katherine Spector was a guest speaker. As a research scholar at the Center on Global Energy Policy at Columbia University, she knows the oil and natural gas markets inside out. The roundtable was a great opportunity for us to explore the analogy that has become so pervasive in our thinking, and our visual scribe did a good job of capturing our discussions.
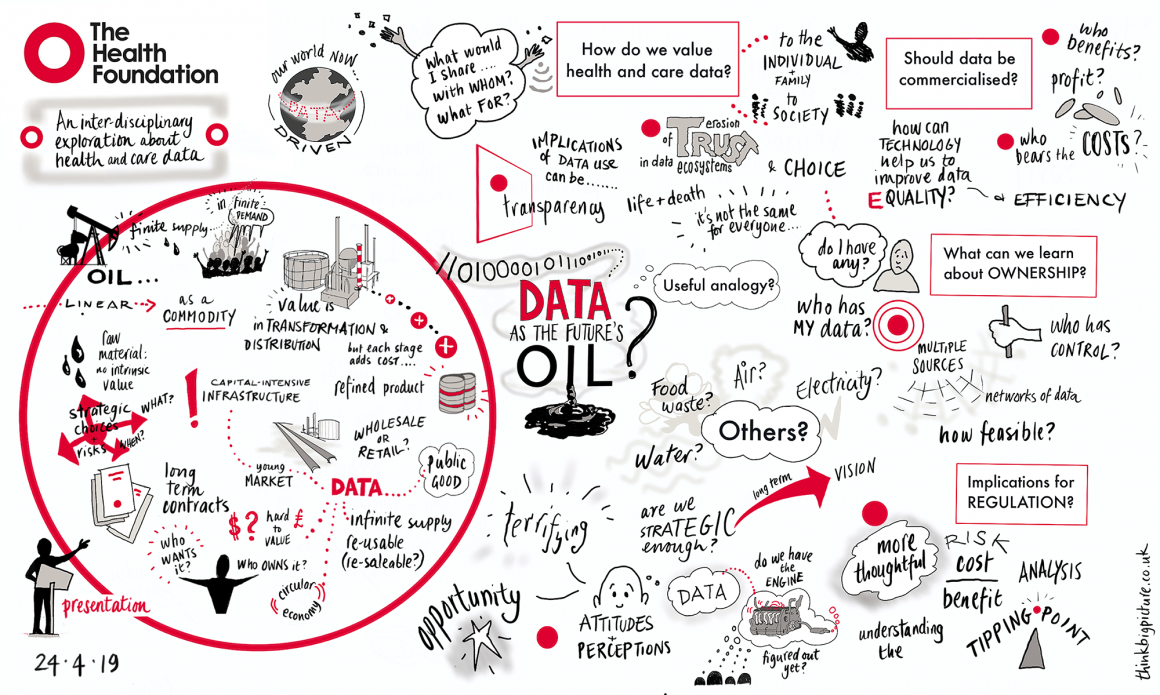
Where the oil analogy is helpful
Like oil, data is worthless in its raw form, but requires refinement, cleaning, structuring and amalgamation. Also like oil, data has a multiplicity of end uses, including algorithms to detect eye disease from images, approaches to help busy hospitals respond to winter pressures and insights from randomised registry trials.
These parallels give us a glimpse of one future for the data system. The oil industry has invested in refineries to transform crude oil into more useful products. Do we need data refineries?
There are lessons from the oil industry. They have placed big bets on infrastructure, but some of their investments have become rapidly outdated, as new products have become available that have shifted what is needed. It's likely that over the next few years we will discover new uses for data. We will therefore need our data infrastructure to be flexible.
This is a big challenge to the ‘data refineries’ currently being built, including the National Commissioning Data Repository, DRIVE and the Digital Innovation Hubs. The emphasis from NHSX on open standards will help, though we probably need more investment in the data managers, architects and engineers who will lead the refinement process.
Of course, there are negative environmental effects from oil (eg spills, fracking, burning petrol and waste plastics). We have become more aware of and more responsive to these ill effects. Likewise, we are becoming more aware of the negative impacts of data – such as the risk of harmful data leaks and the potential for algorithms to automate injustices. Maybe the data community can learn from the approaches that governments have taken to address the negative consequences of oil use (including taxes and plastic bag charges), while acknowledging their limitations.
Where the oil analogy falls down
Analogies, if examined, can be helpful at showing differences (not just similarities). One of the starkest differences is that data is not a finite resource, nor does its value diminish with use. New data is generated constantly, and it can be used many times and by many organisations. Unfortunately, despite the abundance of data, sometimes organisations are tempted to hoard it – the Open Data Institute call this the ‘oil field scenario’. In this scenario, value is concentrated in data monopolies, increasing inequality. If we want the benefits of data to be felt more widely across society, then another analogy might be better.
Comparing data with oil implies that data can be thought of as a commodity. But unlike many commodities, data has a human aspect. It says something about us as individuals, and about our communities. When we sell something on eBay, we don’t have to worry about what happens to it afterwards. Yet if we sell or give away our data, there might be continuing implications we have to deal with long after the transaction has taken place.
This point is neatly illustrated by recent stories about the NHS sharing data with the Home Office. It seems that NHS data (provided by patients) helped trace and potentially arrest people without permission to remain in the UK. This practice puts health care practitioners in a difficult position and has been shown to dissuade people from seeking health care. These consequences are serious, and we risk missing them if we take the ‘data as a commodity’ comparison too far.
Another difference is that data is not property in the same way as oil, yet it can be sold. Indeed, the NHS seems to be increasingly entering into commercial arrangements that involve transfers of data. It’s already a challenge to explain to the public how they can shape decisions about how data about them are used. When we compare data with oil, we send mixed signals to the public who might assume they have more ownership of ‘their data’ than they actually do.
Do we need a different analogy?
Other analogies were suggested during the event. Water is already in common use, as we have 'data lakes' and 'data deluges'. It is attractive because it has health benefits, and ownership is hard to pin down for water, much like data. Blood is another option – Eric Perakslis and Andrea Coravos argue that health care data records are digital specimens and should be treated with the same rigour, care and caution afforded to physical medical specimens. Roads and electricity have also been suggested.
All these analogies are useful, but they show different aspects of the problem. We might need multiple analogies, and to use them lightly. Comparing data with oil might help us think about the negative externalities of data, whereas rivers might help us to acknowledge the shared rights to benefit from the use of this resource. Roads might help us remember that the data system must be maintained as carefully as roads if there is to be public benefit.
Thanks to all the participants of the event for their thoughts – it felt like a rich discussion, and I’m grateful to everyone who contributed on the day, as well as to Anne Bowers, Fiona Grimm, Josh Keith, Jess Morley and Lydia Nicholas who provided helpful pointers on earlier drafts of this blog. Analogies aside, we can learn much from other sectors about how best to tap the potential of data to improve health and care.
Adam Steventon (@ASteventonTHF) is Director of Data Analytics at the Health Foundation
Find out more
Work with us
We look for talented and passionate individuals as everyone at the Health Foundation has an important role to play.
View current vacanciesThe Q community
Q is an initiative connecting people with improvement expertise across the UK.
Find out more

{kind=link}